Stock Market Prediction by LSTM Neural Network
by Riki Imai, Hadi Al Musa
https://riki-imai.github.io/Stock-Market/
Table of Contents
I. Abstract
II. Introduction
II. Related Works
III. Methods
IV. Results
V. Discussion
VI. Conclusion
VII. Ethics
VIII. Future Work and Reflection
IX. Works Cited
Abstract
Stock market prediction is an interest to many investors. With new technologies and the rapid spread of information through social media, an event in one place would affect other parts of the world easily but also poses insights for better stock market prediction 1, such as the sentiment analysis on Twitter having been effective. This project attempts to predict the stock market prices with Recurrent Neural Network (RNN) based on the stock prices data taken from Yahoo Finance. The performance of this model successfully accomplished in the range from about 2% to 8.7% gains for 7-day transactions, depending on the different stocks. We solely depend on the market prices as data for building the stock market prediction model, but future work will incorporate other measures such as sentiments and also various ways to trade, including futures, options, etc.
Introduction
Stock market prediction has always been a topic of interest for investors, financial analysts, and researchers. In recent years, with the growth of machine learning and deep learning, the use of neural networks (NN) for stock market prediction has gained significant attention. NN are computational models that can be trained to recognize patterns and trends in data and can be used to make predictions based on past performance.
The year 2023 has been filled with major financial crises. The bankruptcy of Silicon Valley Bank 2 brought considerable repercussions to the finance system, sentiments, and psychological behavior. IMF issued a Global Financial Stability Report (GFSR) in April 2023, witnessing the changes in sentiments that were observed on Twitter as the results of people’s behavior and reactions “Negative sentiment on Twitter surged, and stock prices tanked after Silicon Valley Bank announced its securities losses.“ 1. These behaviors observed on Twitter indicate stock market prediction, suggesting the need and spread of algorithmic trading presence.
Algorithmic trading tries to accommodate as much information as possible, such as news articles, price movement patterns, trends, sentiments as mentioned above, etc. With the development of computational analysis and algorithms, there is a huge movement toward understanding the stock market quantitatively more and more.
Automating the Prediction of stock market fluctuations has been a difficult matter for a lot of companies trying to do so, mainly because of the number of factors that can affect stock changes and make predicting them perfectly nearly impossible, as presented in the “Black Swan Theory” and/or “random walk theory.”
For example, Eli Lily’s stock dropped by 4.37% after a fake Twitter account impersonating them tweeted with the promise of free insulin 3. Such events create difficulty in predicting daily stock changes with full accuracy.
Another thing to mention is the role of psychological factors and sentiments plays in the stock market. The psychological behaviors are not depicted quantitatively, making accommodating this qualitative information into the quantitative prediction algorithm difficult. There has been an attempt to do so, such as the observed correlation between sentiments and stock market price movements, economic indicators, and company financial reports 4. Many other psychological factors face difficulties in quantitating into the prediction, such as biases and irrational decision-making.
With these factors playing a huge role in the stock market, there has been the observation that theories established in behavioral finance and economics do not depict what it is, such as efficient market theory, which has been the discrepancies between theory and the markets 5. As such, there is more need than ever for behavioral aspects of finance 6, and becoming more critical to explore the realms of human behavior and the cognitive biases in decision-making 7, with some past case study qualitative, personality traits in the financial context 8 as well.
Given the past closing price data for a month, we intend to predict the market price for the next 7 days for multiple stocks, including index funds (S&P500, DOW, etc.) and also each stock. Our program differs from others in a way that it could work with any stocks of your choice; most past programs primarily focused on predicting the specific stock or industry.
Related Works
In recent years, various studies have explored the application of artificial neural networks (ANNs) for stock market prediction. One such study proposes the use of ANNs to predict stock prices, as these networks can recognize patterns and trends in data and can be trained to make accurate predictions based on past performance 9. The accuracy of ANNs in predicting stock prices is affected by various factors such as the network’s architecture, the number of hidden layers and nodes, and the activation function used 9. The study also suggests that incorporating more data, such as news and social media sentiment, economic indicators, and company financial reports, can improve the accuracy of stock price predictions, highlighting the need for ongoing research in this area 9.
Another study implemented a neural network model to predict future movements of stock prices using the Deutsche Börse Public Dataset, which contains stock market data on a minute-to-minute basis 10. To minimize the impact of noise in the data, the researchers averaged ten 1-minute data points into a single data point 10. This approach allowed them to capture trends from the previous 10 minutes and utilize them for predicting stock price movements 10. This research further emphasizes the potential of neural networks in the field of stock market prediction and demonstrates the importance of data preprocessing techniques for improving the accuracy of predictions.
Methods
We use Pytorch and TensorFlow for creating this predictor from scratch. The real stock market data taken from Yahoo Finance has been utilized in this research. The model uses a simple LSTM (Long Short-Term Memory) neural network. LSTM is a type of RNN that can capture long-range dependencies in a sequence, making it suitable for time series data like stock prices.
Our main goal is to achieve a working model while maximizing accuracy. We will measure the performance of this model as well by deciding on buy/sell actions based on the comparison between the predicted value and actual market data.
To build our LSTM-based stock market predictor, we utilize Python and the PyTorch library. We train our model by employing historical stock market data from sources such as Yahoo Finance. Our LSTM network considers the stock’s historic monthly closing prices as input features. It then predicts the stock’s closing price for the next 7 days.
The dataset is preprocessed, normalized, and divided into training and testing sets. We train our model using the training set and evaluate its performance using the testing set. We use evaluation metrics of Root Mean Squared Error (RMSE) to measure the model’s accuracy. This measure give the percentage error of prediction compared to the real values, which provides a measure of how well the predictions match the real values, such as stock prices.
During the training phase, we can experiment with various hyperparameters, such as the number of layers in the LSTM network, the number of hidden units, and the dropout rate. Tuning these hyperparameters might help us achieve better prediction results.
We currently use hyperparameters as below. Additionally, we can explore other optimization techniques, such as learning rate schedules and weight initialization methods, to further improve the model’s performance.
| Train/Validation Split Ratio | Batch Size | Number of Epochs | Learning Rate | Hidden Size (units in each LSTM cell) | Number of Layers | Dropout |
|---|---|---|---|---|---|---|
| 0.8 | 64 | 300 | 0.01 | 64 | 2 | 0.8 |
For the actual transaction, we assume to make a decision a day with the closing price to sell or buy based on the comparison between today’s market price and tomorrow’s expected price. If today’s market price is lower than expected tomorrow’s price, our predictor would recommend to “buy” the stock. If the opposite happens, our predictor yields the recommended action to “sell.” Please note that for the sake of prediction to be simple, our predictor currently considers only closing prices and does not consider transaction costs and options to hold or other transaction methods such as future or option. Our predictor would yield expected gains and losses for these recommended action and overall gains and losses with an accuracy of its predictions if available.
Our predictor currently only accepts the Stock name as an input and predicts the expected price from December 2nd, 2022, but future development will allow a specific timeframe you would like to predict the stock prices.
Results
We accomplished an accuracy of about 96 to 98% accuracy depending on the different stocks. For example, here is our results for some index funds.
Index
| Stock Name | 7-day Gains/Losses | Accuracy |
|---|---|---|
| S&P500 | 4.715958510247087% | 98.39800710345172 % |
| Dow Jones Industrial Average | 2.777528127483042% | 98.9430870054851% |
| NASDAQ | 6.419393572074417% | 97.9430269653437% |
Stocks
For the specific stocks, here are a few of the results from our predictor.
| Stock Name | 7-day Gains/Losses | Accuracy |
|---|---|---|
| Apple (AAPL) | 6.187403413378778% | 98.10325996116931% |
| Alphabet Inc. (GOOG) | 8.71070498232065% | 96.72385255792062% |
Graph
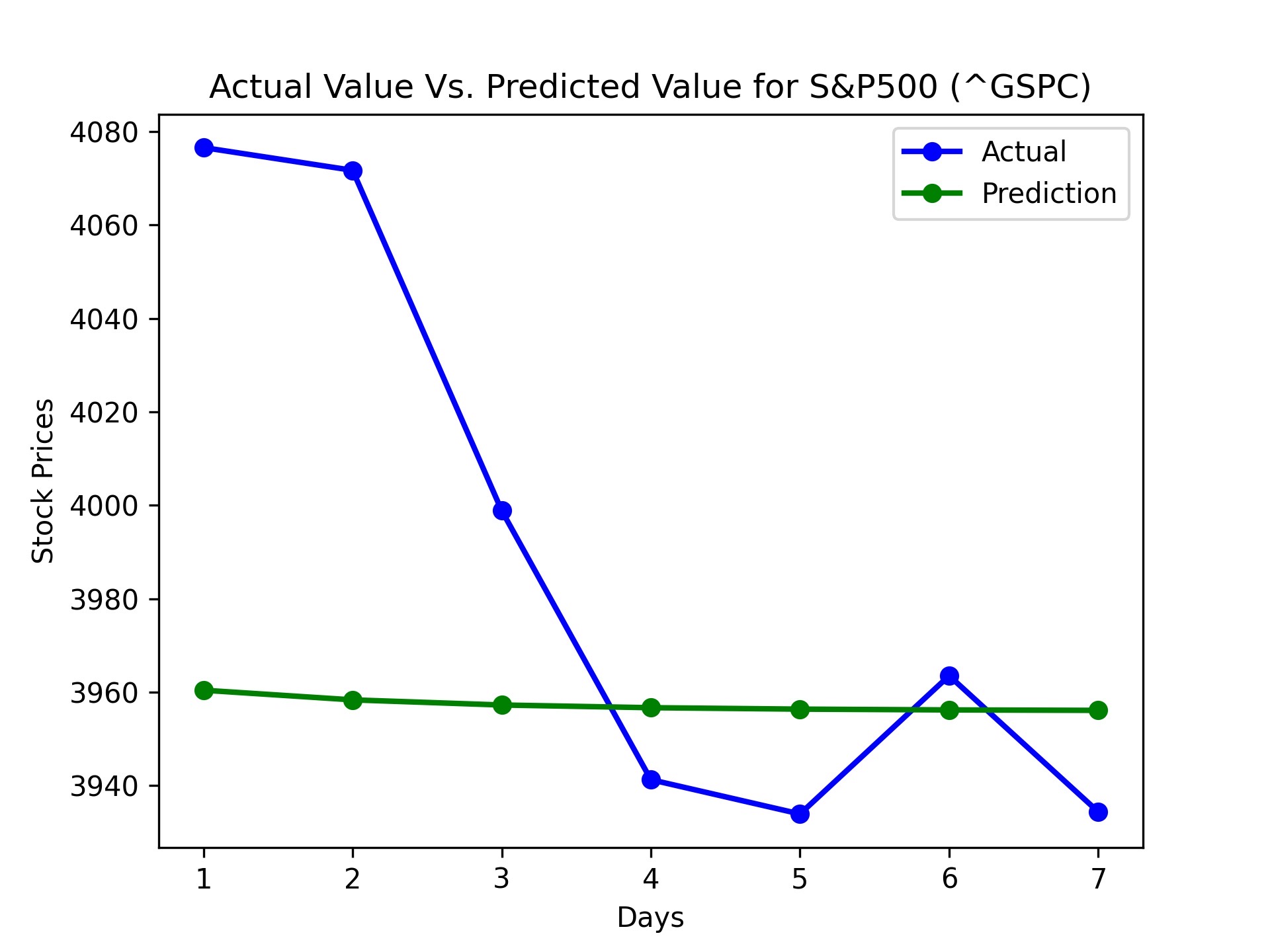
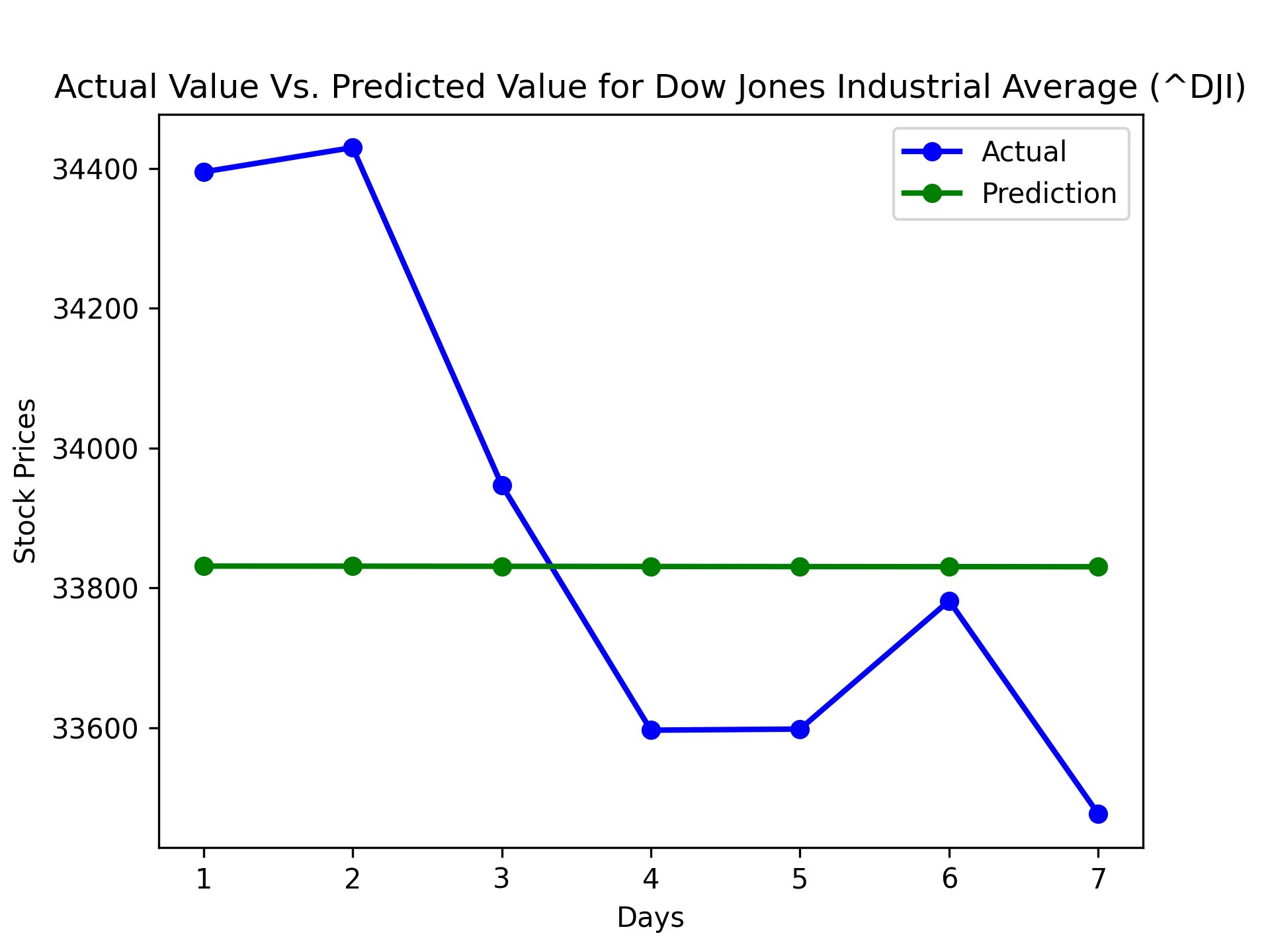
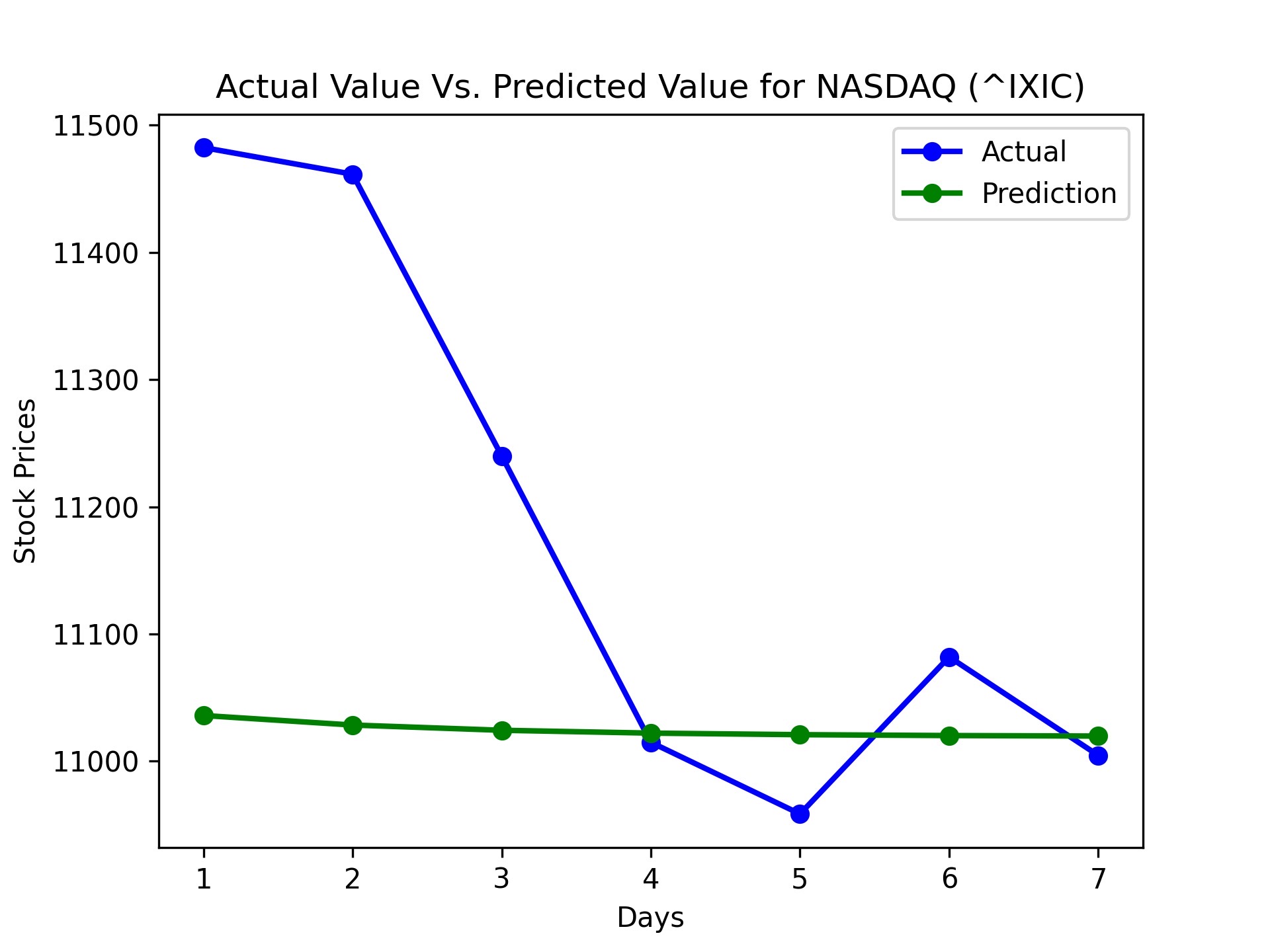
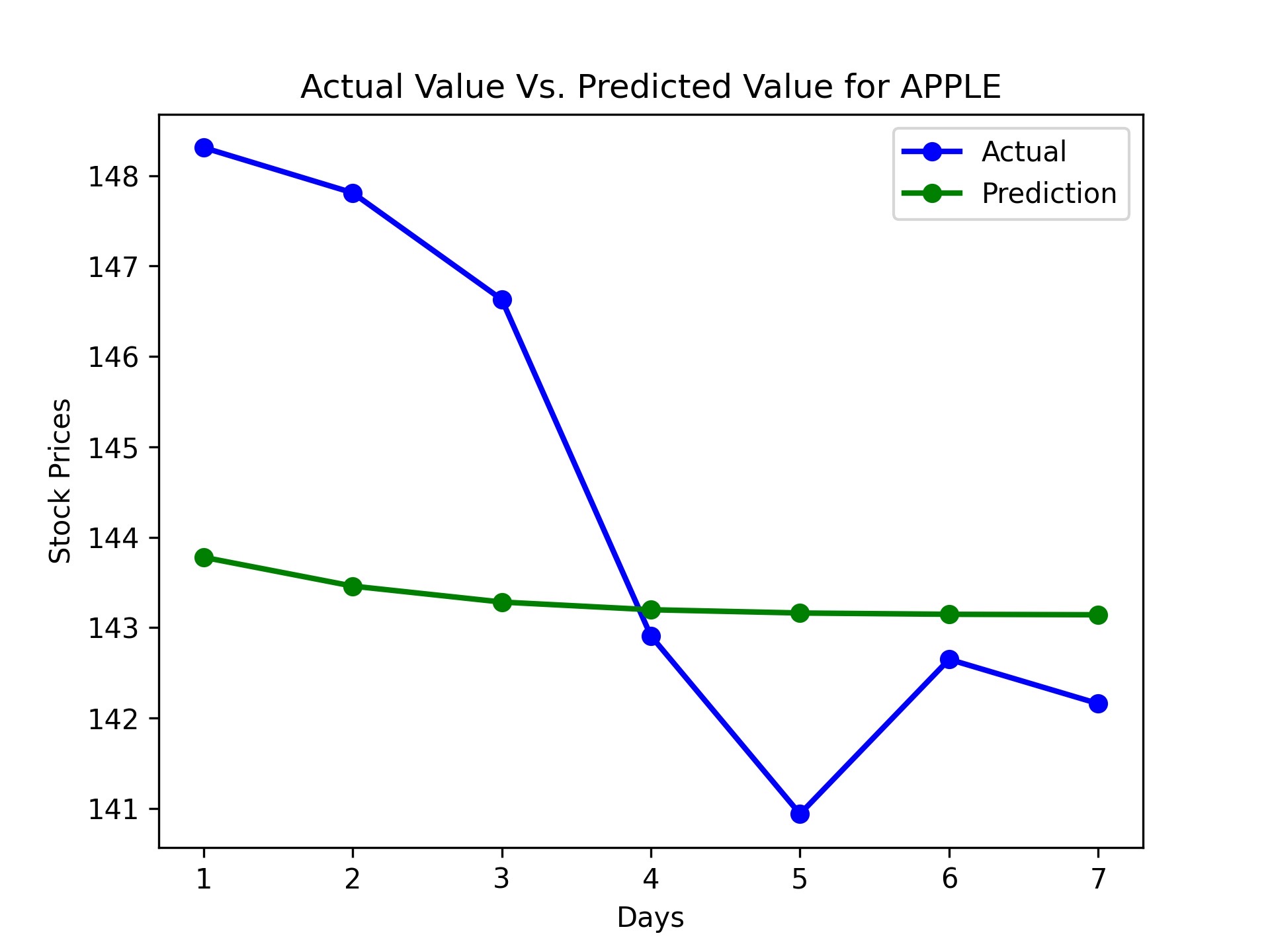
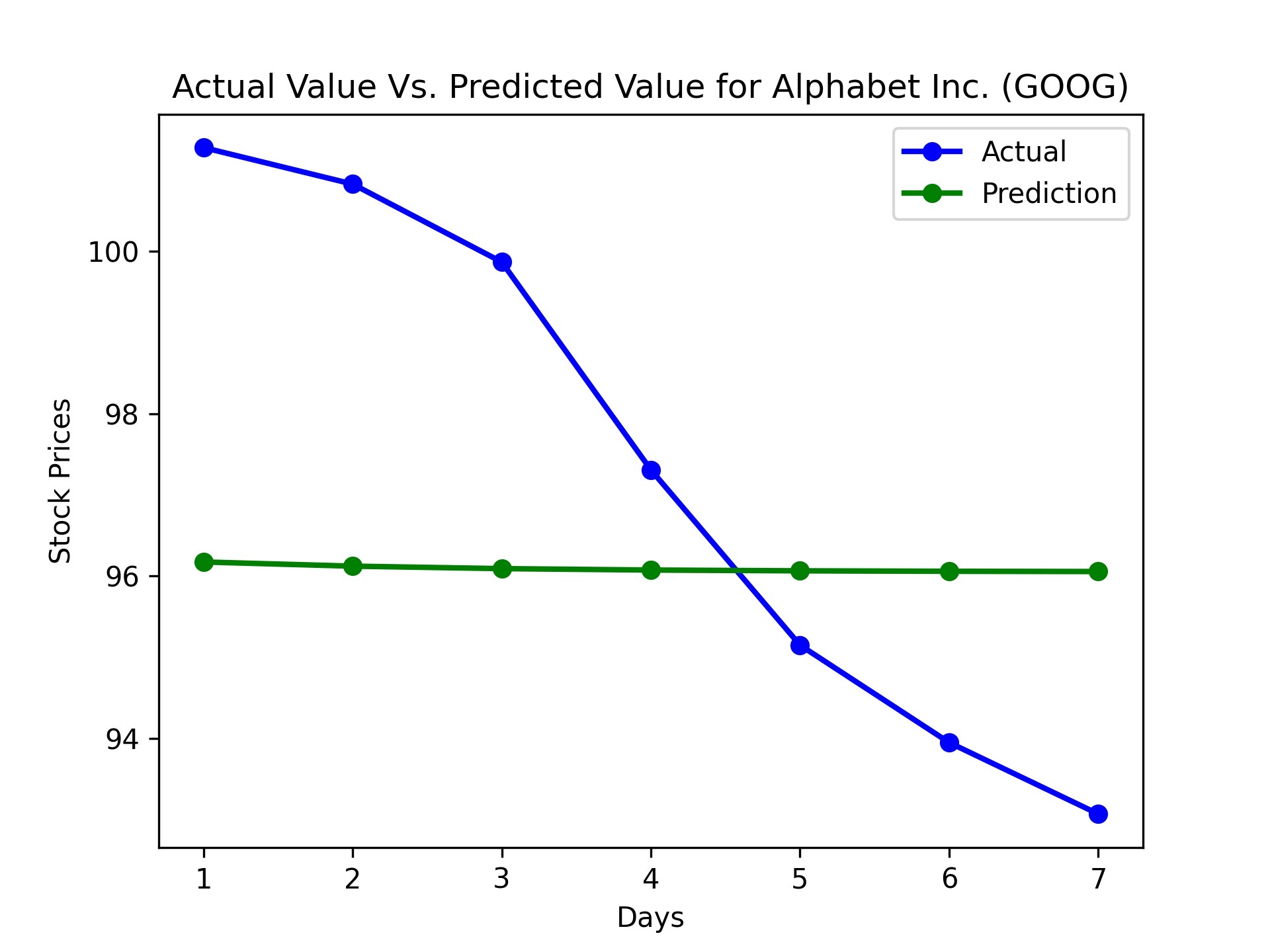
During the evaluation phase, we noticed that the model’s predictions were more accurate for some stocks than others. This could be attributed to the varying levels of volatility and predictability in different stocks, as well as the specific timeframes chosen for training and testing. Furthermore, we observed that the model performed better in predicting the overall trend of stock prices rather than the exact values.
Based on predicted prices and actual prices with recommended actions, our program accomplished around 2.7% to 8.7% gains, with accuracy ranging from 96% to 98%. This model usually has the highest return for the first day of prediction because uncertainty increases as the day progresses from model data.
Hyperparameter comparison:
We found that these hyperparameter works best for the range of 2022-11-01 to 2022-12-01. Further optimization might improve these results as well.
| Train/Validation Split Ratio | Batch Size | Number of Epochs | Learning Rate | Hidden Size (units in each LSTM cell) | Number of Layers | Dropout |
|---|---|---|---|---|---|---|
| 0.8 | 64 | 300 | 0.01 | 64 | 2 | 0.8 |
Discussion
The results of our stock market prediction model serve as a stepping stone for further exploration and development of LSTM-based models for financial time series forecasting. Our experience with this model has highlighted several areas of potential improvement, which could lead to a significant enhancement in prediction accuracy.
Firstly, incorporating a broader range of features could improve the model’s ability to capture the complex relationships between different factors affecting stock prices. By considering factors such as social media sentiment, economic indicators, and company financial reports, our model may become more robust and better equipped to predict stock prices.
Secondly, ensemble methods could be employed to improve prediction accuracy further. Combining LSTM networks with other machine learning techniques or using multiple LSTM models with different input features could yield more accurate predictions by leveraging the strengths of each approach.
Another crucial aspect to consider is the role of uncertainty in stock market predictions. Bayesian NNs, as mentioned in the literature review, can provide reasonable predictions and quantify the uncertainty of those predictions. Incorporating uncertainty measures into our model can be valuable for investors as it offers an additional dimension for decision-making.
Lastly, addressing the issue of overfitting and exploring advanced regularization techniques could contribute to better generalization of the model. This would result in more reliable predictions when applied to new, unseen data.
Conclusion
The challenges associated with stock market prediction, such as the complex interactions between various factors influencing stock prices, make this task inherently difficult. When there are unexpected events, this model will find it hard to predict such an occasion as a NN model. This model, however, captures the patterns and will likely catch these dropping trends for example. We are not certain how much this could benefit such an irregular occasion, but generally predicts the trend of stocks and yields a favorable return only with a transaction a day.
With further improvements, our model could become a valuable tool for investors, financial analysts, and researchers in making more informed decisions. Our future work will include different ways of transactions such as Options and Future, multiple parameters, more detailed price movements such as a-minute price, and allow more than one daily transaction. This also does not consider the transaction cost yet, and future work will have a recommended action to “hold” instead of “buy” or “sell.”
Ethics
When considering the ethics of our project, it is important to address several questions and concerns. The question of whether we should even be attempting to predict the stock market is relevant. However, understanding the potential growth of a company and analyzing the audience’s perception can be useful, as the stock market reflects various opinions and information.
There will inevitably be imperfections in our attempts to predict the stock market due to its inherently chaotic nature, as described by the “random walk theory.” To handle potential appeals or mistakes, we will focus on obtaining the most accurate average prediction line possible.
Bias is a concern in any dataset, and although the stock market data itself may not be directly biased, the actions of humans buying and selling stocks introduce some level of bias. We will not make any specific efforts to minimize this bias, as it is already incorporated into the market’s movements.
We anticipate that different industries and companies may exhibit different patterns in their stock movements. To address this, our initial focus will be on a few companies within a single industry, with the potential for expansion later.
Misinterpretations of results can be an issue, particularly since stock market data often contain noise. To prevent this, we will emphasize the randomness in financial markets and discuss established theories that highlight this.
Lastly, the issue of privacy and anonymity is crucial. Stock market prices do not reflect individuals’ personal information and remain anonymous, as there is no way to determine who is responsible for specific trades using only quantitative stock market data. This ensures that our project does not infringe on individuals’ privacy or anonymity.
Future work and Reflection
To enhance the performance of our LSTM-based stock market prediction model, future work should focus on the following areas:
-
Fine-tuning the model’s hyperparameters: Experimenting with different network architectures, hidden units, dropout rates, and other hyperparameters can potentially improve the model’s prediction accuracy. In addition, some near-future adjustments we plan to make include but are not limited to: Changing the time slot for the training data collection, experimenting with low-high volatility companies, adding sell/buy action recommendations, and including various trading ways, such as futures, options, etc.
-
Incorporating additional features: Considering factors such as social media sentiment, economic indicators, and company financial reports can make the model more robust and better equipped to predict stock prices. In addition, adding graphic plots would make understanding the results more efficient.
-
Exploring ensemble methods: Combining LSTM networks with other machine learning techniques or employing multiple LSTM models with different input features can lead to more accurate predictions.
-
Investigating uncertainty measures: Incorporating Bayesian NNs or other methods to quantify the uncertainty of predictions can provide valuable insights for investors. Addressing overfitting and advanced regularization: By tackling the issue of overfitting and exploring advanced regularization techniques, our model’s predictions could become more reliable when applied to new, unseen data.
-
Performance comparison with other models: As we improve our model, it is essential to compare its performance with other existing models, such as traditional statistical models or alternative machine learning approaches. This will provide valuable insights into the model’s strengths and weaknesses and guide further refinements.
-
Exploring alternative deep learning architectures: Besides refining the existing LSTM model, it would be beneficial to investigate other deep learning architectures, such as Transformer models or Convolutional Neural Networks (CNNs), to determine whether they can yield better results for stock market prediction.
-
Personalized stock market predictions: Once our model’s performance has been optimized, we could explore the potential of personalizing stock market predictions for individual investors. This would involve tailoring the model to consider specific investment goals, risk tolerance, and other individual factors, allowing investors to make more informed decisions based on their unique circumstances.
-
Integrating the model into a user-friendly platform: As the final step, we can work on integrating our refined stock market prediction model into a user-friendly platform or application. This would enable a broader audience to access and benefit from our model’s predictions, making the stock market more approachable and understandable for both seasoned investors and novices alike.
-
Trading limits: We only make a single trade a day based on the decision made by comparison between actual endprice from the day before and predicted price for the day. We do not consider the options to hold, so that is one thing we might incorporate in the future work of long-holding stocks.
-
Transaction costs: We do not consider the transaction costs as real stock market life.
By focusing on these areas for future work, we can continue to refine and improve our stock market prediction model, ultimately providing valuable insights and tools to investors, financial analysts, and researchers in finance.
Looking back on the project, we recognize several areas where we could improve in future iterations. Firstly, we would invest more time and effort in exploring additional data sources such as social media sentiment, economic indicators, and company financial reports to build a more comprehensive dataset. This could potentially lead to a more accurate prediction model. Secondly, experimenting with different model architectures and techniques could have potentially improved the performance of our stock market predictor. In the future, we would consider exploring alternative deep learning architectures, such as transformers or attention mechanisms, and incorporating ensemble methods to enhance the model’s performance. Finally, we would allocate more time for fine-tuning hyperparameters, as this could significantly impact our predictions’ accuracy.
Works Cited
-
IMF. (2023, April 11). Global Financial Stability Report, April 2023. Global Financial Stability Report. Retrieved April 13, 2023, from https://www.imf.org/en/Publications/GFSR/Issues/2023/04/11/global-financial-stability-report-april-2023 ↩ ↩2
-
New York Times. (2023). Parent company of silicon valley bank files for bankruptcy - New York Times. Retrieved May 2, 2023, from https://www.nytimes.com/2023/03/17/business/svb-silicon-valley-bank-bankruptcy.html ↩
-
Lee, B. Y. (2022, November 14). Fake Eli Lilly Twitter account claims insulin is free, stock falls 4.37%. Forbes. Retrieved May 1, 2023, from https://www.forbes.com/sites/brucelee/2022/11/12/fake-eli-lilly-twitter-account-claims-insulin-is-free-stock-falls-43/?sh=482ad98241a3 ↩
-
Shen, J., & Shafiq, M. O. (2020). Short-term stock market price trend prediction using a comprehensive deep learning system.Journal of Big Data, 7 (1). https://doi.org/10.1186/s40537-020-00333-6 ↩
-
Sharma, A., & Kumar, A. (2019). A Review Paper on Behavioral Finance: Study of Emerging Trends. Qualitative Research in Financial Markets, 12(2), 137–157. https://doi.org/10.1108/qrfm-06-2017-0050 ↩
-
Hirshleifer, D. (2015). Behavioral finance. Annual Review of Financial Economics, 7(1), 133–159. https://doi.org/10.1146/annurev-financial-092214-043752 ↩
-
Costa, D. F., Carvalho, F. de, & Moreira, B. C. (2018). Behavioral Economics and behavioral finance: A bibliometric analysis of the scientific fields. Journal of Economic Surveys, 33(1), 3–24. https://doi.org/10.1111/joes.12262 ↩
-
De Bortoli, D., da Costa, N., Goulart, M., & Campara, J. (2019). Personality traits and investor profile analysis: A behavioral finance study. PLOS ONE, 14(3). https://doi.org/10.1371/journal.pone.0214062 ↩
-
RK, D., & DD, P. (2010). Application of artificial neural network for stock market predictions: A review of literature. International Journal of Machine Intelligence, 2(2), 14–17. https://doi.org/10.9735/0975-2927.2.2.14-17 ↩ ↩2 ↩3
-
Originate. (n.d.). Retrieved February 28, 2023, from https://www.originate.com/thinking/predicting-stock-market-movements-using-a-neural-network https://github.com/Originate/dbg-pds-tensorflow-demo ↩ ↩2 ↩3